Ranjith Parakkal, Uncanny Vision
EDN
Comparing smart-phone performances - and the SOC and processor cores that drive them - has been a hotly discussed topic of late. More so now, since Intel is trying to challenge ARM in the low-power mobile space with the Atom processor, while ARM is trying to challenge Intel in the server space with the Cortex-A53 and A57. There have been articles written previously comparing the performance of ARM-based phones Vs Atom-based ones - and many benchmarks too- but perhaps not one that compares Cortex-A15 Vs A9 Vs Intel Core i3 from an actual developers perspective. In this post I will try to share my experience working on optimizing computer vision algorithms, pedestrian detection in particular, and compare the performance of the same on the three processors.
Computer vision in layman's terms can be described as analytics that can gleaned from a video or an image. Face detection and recognition are easily understood examples of computer vision.
So why use a computer vision algorithm for benchmarking? Vision algorithms are very compute intensive, and with increasing availability of processing power, these algorithms are finding more application in the real-world. Unlike other compute intensive tasks of earlier days like graphics and video codecs, vision algorithms usually don't have a dedicated engine inside the processors to accelerate them.
Consequently, all the computation is done on the CPU itself, and vision algorithms are usually a good mix of fixed and floating point number crunching and a good amount of conditional executions too - making them a decent choice for benchmarking CPUs.
Pedestrian detection - the industry term for detecting humans in videos - is one of the challenging problems that automotive makers are working on for next generation safety using cameras. The most popular algorithm for pedestrian detection is HOG (Histogram of Oriented Gradients) proposed by Navneet Dalal and Bill Triggs. Its available as part of OpenCV - an open source computer vision library with a permissive license - and is pretty well optimized. However it's still not fast enough to run real-time on most processor architectures.
On an Intel Core i3 machine, using a single core running at full clock doing an exhaustive search for humans with a minimum size of 64×128 pixels on a VGA sized image, is 13 times slower than desired. To make things worse, the automotive industry usually can't afford to put a Core i3 processor in a car due to power issues. So most of the processors that are used have an ARM core (Cortex-A8, A9 and now A15) plus a DSP/FPGA inside it. So the need of the day is clearly to optimize HOG further - a lot further. We chose the ARM core for optimization because of its ubiquity.
Optimizing an algorithm basically includes two steps. The first step is what we call C optimizations and are mostly processor agnostic. In the second step, we focus more on ARM architecture, primarily the Neon instructions - similar to SSE instructions in x86. The basic algorithm though remains the same and so does the output (detection accuracy).
We used the following cores for our measurement:
- Cortex-A15 - 1.2 GHz 2 MB cache running Android on Exynos 5250 Arndale board (also tested on OMAP5432)
- Cortex-A9 - 1.2 GHz 1MB cache running Android on OMAP 4430 Panda Board
- Core-i3 - 2.99 GHz 4 MB cache running Linux Ubuntu
- Core-i3 - 1.2 GHz 4 MB cache running Linux Ubuntu
We included an additional measurement of the same Core i3 clocked down at 1.2 GHz to get one more data point that is the same as the ARM clocks. We didn't include i5 and i7 in the test as their main differentiators are the number of cores, hyper threading, higher clocks and larger caches and not so much the instruction set and the architecture itself, which is what we intended to compare.
Power optimizations were switched off to ensure that the cores are always clocked at the same value. The HOG application was kept single threaded to ensure that it runs only on one core. The code was always compiled with the compiler set to highest optimization level, with SSE and Neon flags enabled.
Results
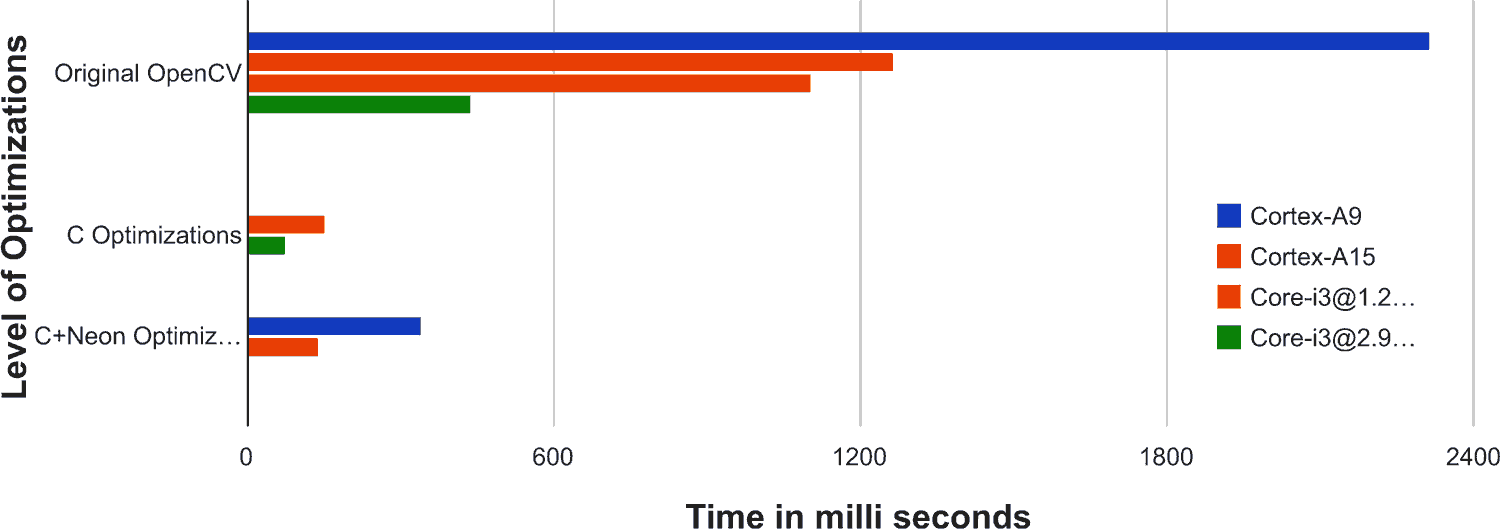
Profile details for HOG are shown below in milliseconds. Some rather surprising details emerge.
HOG OpenCV
Cortex-A9 - 2320 ms
Cortex-A15 - 1265 ms
Core i3@1.2 GHz - 1107 ms
Core i3@2.99 GHz - 439 ms
HOG with C Optimizations
Core i3@1.2 GHz - 152 ms
Core i3@2.99 GHz - 74 ms
HOG with Neon and C Optimizations
Cortex-A9 - 340 ms
Cortex-A15 - 138 ms
 |
| Performance benchmarks in milliseconds (lower is better) |
For those who are wondering if this much optimization is sufficient, there are other tricks to get this running real-time on an actual system.
What the statistics reveal
It proves beyond reasonable doubt, that A15 does indeed give nearly twice the performance of an A9, at the same clock, though one must admit that the A15 with a bigger L2 cache has a little bit of an unfair advantage over A9.
A more interesting aspect of these numbers is that when both Cortex-A15 and Core i3 were clocked at the same rate, 1.2 GHz, the performance of the 2 CPUs were not too different for the original OpenCV HOG. Cortex-A15 (1265 ms) is slower than Core-i3@1200 MHz (1107 ms) by only around 14%, in this case. It would be an error though, to generalise this for all algorithms.
So is Intel within ARM’s reach?
To be fair to Intel, Core-i3@1.2 GHz using only C optimizations, managed to almost keep up with the fully optimized code on A15, though we suspect that the compiler may have already done a great job to use SSE instructions using our data-parallelism friendly C code. Besides Intel has higher clocks (core i7 can run at 3.8 GHz in turbo mode) and hyper-threading, which would help in a multi-threaded environment, to fall back on.
Perhaps the most interesting statistic is that the fully optimized version of HOG running on Cortex-A15 (139 ms) managed to outdo the original OpenCV version of HOG on the 2.99 GHz clocked Core i3 (439 ms) by over 3x, despite running 2.5 times slower and having half the cache. This result shows that with some software optimization a Cortex-A15 can challenge a Core i3, and maybe even beat it at its own game.